Reports indicate that Meta AI is likely not delivering the best results, this could limit its progress on AI agents
While it’s hard to make an accurate assessment on the trajectory of Meta AI since DeepSeek disrupted the industry and the Llama 4 is yet to be released, current reports suggests that not everything is going on well with it. For instance, there are reports that Meta business AI agents are not delivering as expected and the company is even considering using DeepSeek’s model. The report that Meta’s internal coding agent is using GPT also signals underperformance of Meta’s Llama model. There were also reports that the upcoming model is likely to underperform DeepSeek and Meta’s engineering team was scrambling to resolve this situation. Similarly, during a call with Morgan Stanley, Meta’s chief of product Chris Cox failed to confirm when the Llama 4 will be released despite Mark Zuckerberg having promised that it will be released in early 2025. He only confirmed that they have started using “distillation” process to reduce training costs. However, distillation process will only lead to great results if the parent model is great. While Meta’s relationship with around 200 million small businesses will give it an hedge when it comes to monetizing the AI agents, these agents will need a great model to work efficiently.
Manus, an AI agent that was launched on March 6 has received a lot of hype, with some people calling it the “second Deepseek”. Manus says it uses a combination of existing and fine-tuned AI models which include Anthropic’s Claude and Alibaba’s Qwen, to perform tasks such as buying real estate and programming video games. Its scientist Yichao “Peak” Ji has even said the Manus outperforms Open AI’s deep research and Operator. However, some testers have found it promising but not perfect yet. For instance;
A test by Business Insider established that while Manus structures tasks correctly, it stumbles in execution and even uses fake or simulated data.
Kyle Wiggers, Techcrunch’s said Manus crushed 10 minutes into the first test: " order a fried chicken sandwich from a top-rated fast food joint in my delivery range". On the second test, it didn’t complete the ordering process or provide a checkout link. Manus also provided broken links on the second test which involved booking a flight from NYC to Japan. It also errored when asked to build Naruto-inspired fighting game.
A test by Caiwei Chen of MIT found it to be highly intuitive but with limited scope and high system crashes and server overload. He said in two of the three tasks, it provided better results than ChatGPT DeepResearch, though it took longer time.
“I found that using it feels like collaborating with a highly intelligent and efficient intern: While it occasionally lacks understanding of what it’s being asked to do, makes incorrect assumptions, or cuts corners to expedite tasks, it explains its reasoning clearly, is remarkably adaptable, and can improve substantially when provided with detailed instructions or feedback.” He wrote.
Analyst Dan Salmon of New Street Research believes that the likes of Meta will still have a significant advantage over the likes of Manus due to their existing user base.
“Like other newly developed products from startups, Manus lacks established businesses with billions of users already to whom new AI products can be pushed by Google, Amazon and Meta,” Salmon wrote. “These companies will continue to hold this significant advantage for some time.”
Assessment
In my opinion, the fact that Manus is able to receive such a hype by using the less celebrated Anthropic’s Claude and Alibaba’s Qwen reduces the risks for Meta Platforms. For instance, if Meta is unable to deliver superior performance through its upcoming models, it could use that of Open AI or DeepSeek to build AI agents (while working on its own models) as it has been rumored.
I=8 Meta to release Llama 4 this month after delaying it twice, timeline could still change
Meta is planning to release its Llama 4 model later this month, after delaying it at least twice, the Information reported citing two people familiar with the matter.
According to the sources, Meta could push back the release of Llama 4 again.
The report indicated that one of the reasons for the delay is during development, the model didn’t meet Meta’s technical benchmarks, especially in reasoning and math tasks.
The report also adds that Llama 4 was less capable than OpenAI’s models in human-like voice conversations.
Llama 4 is expected to borrow certain technical aspects from DeepSeek, such as mixture of experts method, which trains separate parts of the model, making them experts in certain fields.
Meta could release the model during its Llamacon event scheduled for April 29.
Sam Altman announced today that GPT-5 will arrive in a few months and that it will be much better than they originally thought.
I=9 Meta launches Llama 4 Scout and Maverick, claims best-in-class performance
Yesterday, Meta Platforms released two models of its Llama 4 model, the Llama 4 Scout and the Llama 4 Maverick.
It said the Llama 4 Scout has 17 billion parameters and 16 experts, outperforms previous Llama models, fits on a single NVIDIA H100 GPU, supports a 10 million token context window, and beats Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 on widely reported benchmarks. It added that it’s the best multimodal model in its class.
It said Llama 4 Maverick has 17 billion parameters and 128 experts, is the best multimodal model in its class, beats GPT-4o and Gemini 2.0 Flash on reported benchmarks, matches DeepSeek V3 on reasoning and coding with less than half the parameters, and offers a best-in-class performance-to-cost ratio.
It pointed out that both models were distilled from Llama 4 Behemoth, a 288-billion-parameter model with 16 experts that outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks, though it’s still in development.
Initial Tests on Llama 4 Maverick and Llama 4 Scout
Initial tests (Notion page) on Llama 4 Maverick and Scout contradict the benchmarks provided by Meta. Most testers have raised concerns about their coding performance, lack of step-by-step reasoning and being less conversational compared to GPT 4 (GPT 4o Deep Research). There are also reports that its context window (short-term memory) may not be genuine.
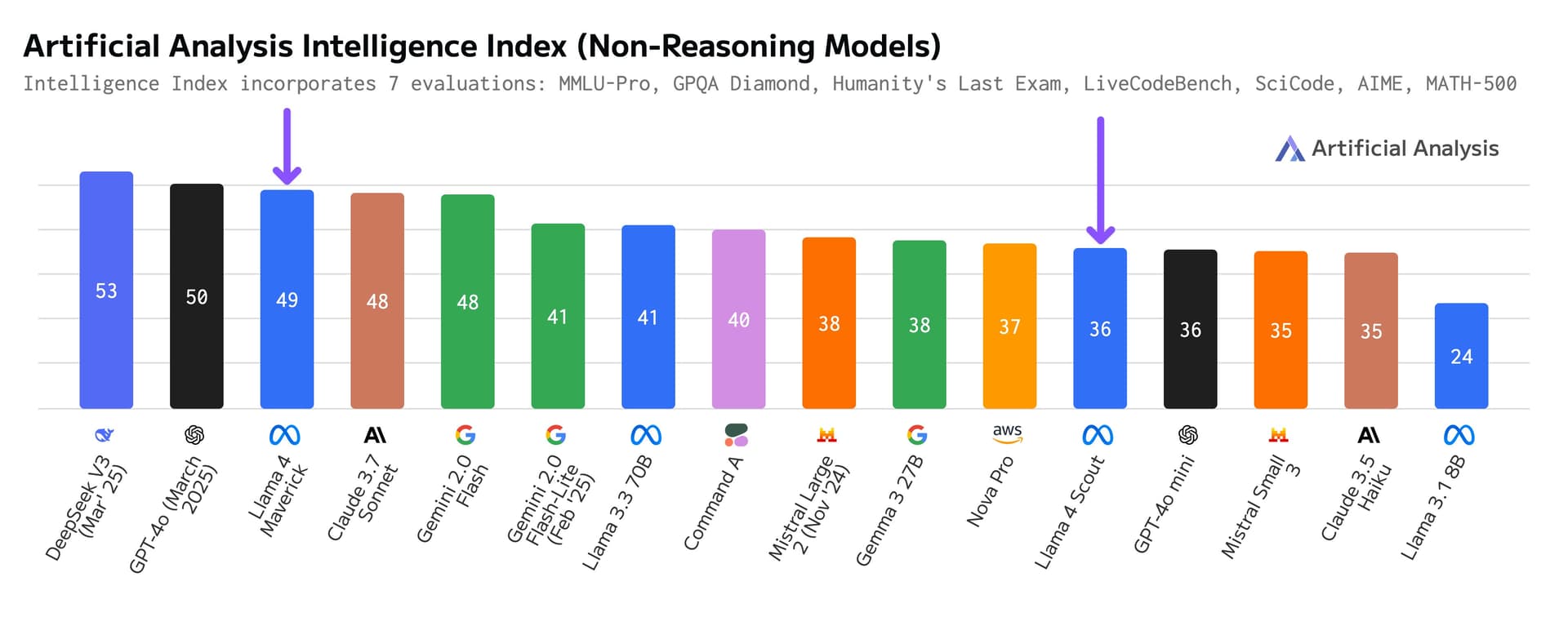
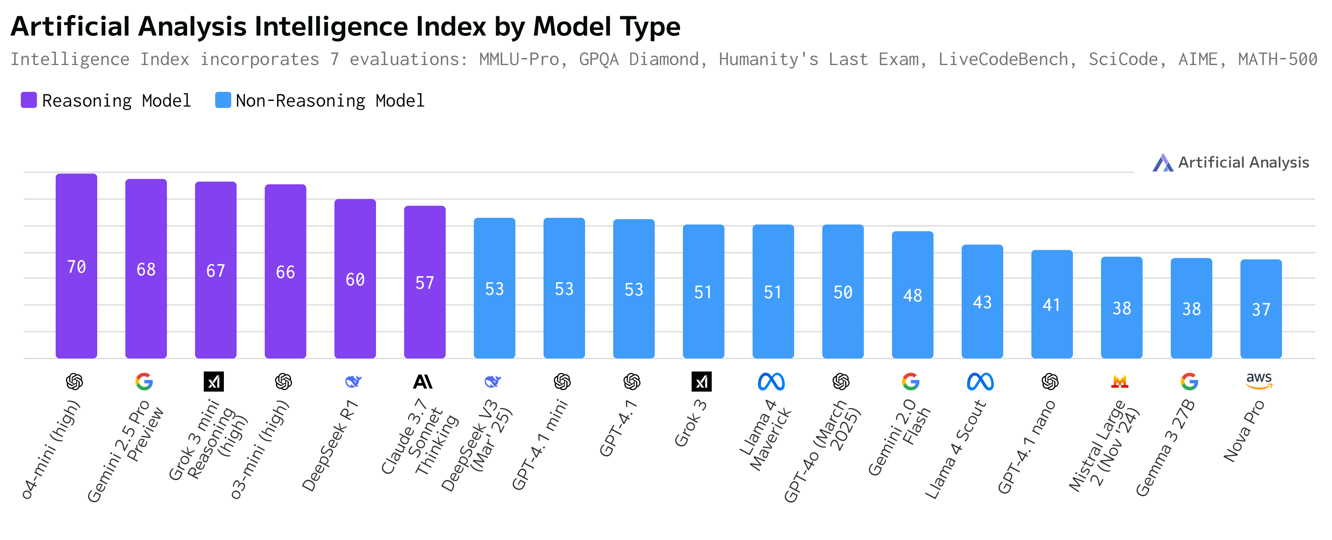
According to Artificial Analysis (a seemingly credible source), Maverick ranks third, behind DeepSeek V3 and GPT-4o, while Scout trails Gemini 2.0 Flash-Lite and Gemini 3 27B. Although neither model tops the charts, Maverick does show improvement over Llama 3.3 70B and is more efficient than DeepSeekV3. However, it is worth noting that the current Gemini 2.0 Flash has 1 million context window, hence Maverick’s ranking could fall further once Google announces its new models next week.
Generally, I think Meta released these models to buy time following The Information’s report, which indicated that it was running into delays with the Llama 4 model, until it launches the more advanced model, Llama 4 Behemoth.
I will continue researching on its user experience tomorrow and update my findings.
I=8 Meta’s Head of Generative AI said initial inconsistencies with Llama 4 models are temporary deployment issues
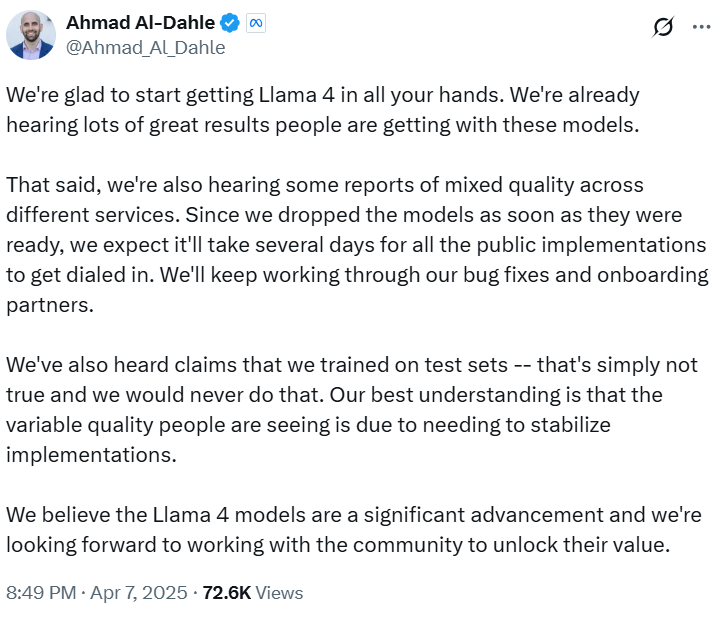
Meta’s Head of Generative AI, Ahmad Al-Dahle, says the initial inconsistencies are due to short-term deployment issues, not flaws in the models themselves.
He denied the rumor going around that the company trained its model to perform well on specific tasks while concealing weaknesses.
Meta’s FAIR is “dying a slow death”, the Fortune reported
According to former employees, Meta’s FAIR is “dying a slow death”, the Fortune reported.
The Fortune notes that more than half of the 14 authors of the original Llama research paper published in 2023 left the company six months later while at least eight top researchers have left over the past year.
Two of the departing researchers went on to found Mistral AI, which is now valued at $6 billion.
Yann LeCun who is currently leading FAIR temporarily as the company searches for Pineau’s replacement, calls it a “new dawn” in the company.
“It’s more like a new beginning in which FAIR is refocusing on the ambitious and long-term goal of what we call AMI (advanced machine intelligence),” LeCun said.
The former employees pointed out that fundamental research within Big tech companies have slowed and that FAIR now gets less computing power for its projects than the Gen AI team.
Assessment
I agree with the insiders that it’s natural for the company to shift focus from the fundamental research to consumer-facing AI products given that AI developments in the industry is rapidly changing. However, it’s not good to see the founding Llama researchers leaving the company. This change in strategy could explain why Joelle Pineau, the head of FAIR recently left the company.
LMArena apologised after Meta used experimental version of Llama 4 to achieve a high scores, performance of Llama 4 models haven’t improved yet
LMArena had to apologize to developers after it was established that Meta used an experimental version of Llama 4 to achieve a high scores.
“Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future,” LMArena wrote in X.
Llama 4 maverick currently ranks below popular models such as GPT-4o, Deepsek V3, Claude 3.5 Sonnet, and Google’s Gemini 1.5 Pro.
Current rankings by Artificial Analysis also puts Lama 4 Maverick in the fifth position among non-reasoning models.
It’s evident that the performance of Llama 4 models hasn’t improved in the past two weeks, despite Meta’s head of Gen AI promising that the company was working to fix the bugs causing quality issues. LMArena’s confirmation that Meta used an experimental version is also not good for the company’s credibility.
I=4 Meta AI chatbots encourage “explicit” content, the Wall Street Journal Reported
According to tests by the Wall Street Journal and comments from employees, Meta AI chatbots are encouraging “explicit” content.
Citing people familiar with the matter, the Wall Street Journal noted that Zuckerberg pushed for loosening of guardrails around the bots so as to make them as engaging as possible.
Meta Platforms will hold its LlamaCon event today, where it is expected to showcase its latest AI tools and developments. Below is my preview of the event.
Llama 4 Developments:
Comments regarding the Llama 4 models will take center stage. Following concerns about the underperformance of initial Llama 4 versions, the market will look for reassurance, possibly through performance metrics related to the yet-to-be-launched Llama 4 Behemoth model. Updates on Meta’s progress with AI agents will also be closely monitored.
CapEx Guidance:
Analysts largely expect Meta to reiterate its CapEx guidance of $60–65 billion for 2025, as generative AI is seen as a long-term strategic priority. If Meta signals a reduction in CapEx investment — perhaps citing tariff headwinds — the market may react negatively, especially since other players such as Alphabet have reaffirmed their CapEx commitments.
Meta AI User Base and New Products:
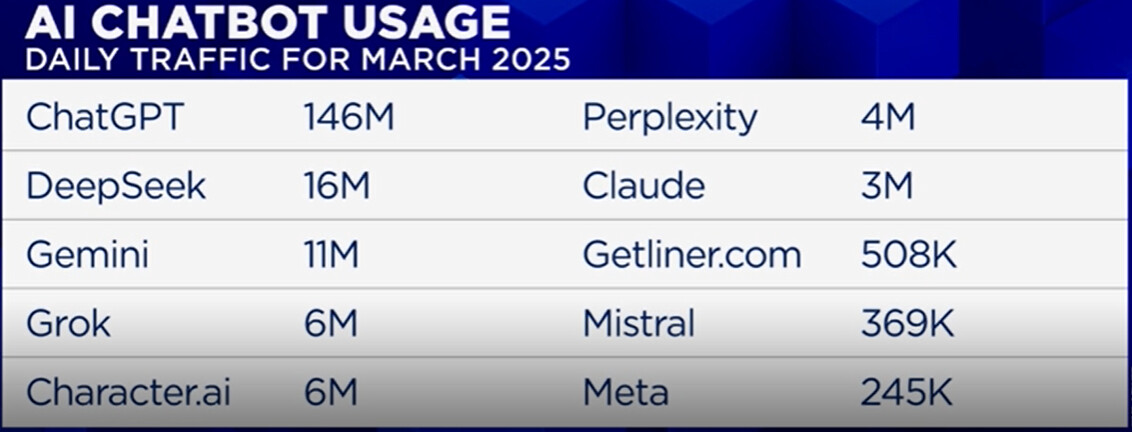
The market will seek updates on the Meta AI user base. The most recent insights from the company indicated that Meta AI has 600 million monthly active users and has received 1 billion downloads. If user growth appears underwhelming, sentiment could turn negative.
Additionally, reports suggest that Meta may introduce a standalone Meta AI app. A confirmation of these reports could be positive for the stock, as some analysts believe Meta’s feed algorithms on Facebook and Instagram are cannibalizing Meta AI usage.
Partnerships and Cost Sharing:
Recent reports indicated that Meta had approached Amazon and Microsoft to help share the cost of training the Llama models, but both reportedly declined.
Insights into current collaboration efforts could emerge during the scheduled interview between Mark Zuckerberg and Microsoft CEO Satya Nadella today at 4:00 PM PDT.
Overall, I think the stakes are high going into the event, given the tariff uncertainty and the underperformance of the Llama 4 models. As such, I expect elevated stock volatility as the event unfolds.
Meta debuts Meta AI app which shows how your friends use AI
Meta Platforms has introduced the Meta AI app, which it says learns user preferences, is personalized, and remembers context.
The app includes features typical of AI assistants, such as the ability to type or talk with it, generate images, and search the web. Its most distinctive feature is the Discover feed, where users can explore and share how others are leveraging AI.
Meta’s VP of product Connor Hayes expects majority of Meta AI’s usage to come from places like the search bar on Instagram.
The voice feature doesn’t have access to the web or real-time information and Meta notes that you may encounter “technical issues or inconsistencies”.
Hayes told the Verge that Meta AI has reached almost one billion users (January 2025: 700 million monthly actives).
CNBC reported in early March that Meta was planning to launch a standalone Meta AI app.
The most interesting part of the LlamaCon was the release of Llama API, which should enable Meta to reach more business users and developers
The most impactful announcement from the first session of LlamaCon, chaired by Chris Cox, was the launch of the Llama API in limited preview (min 46:55), which allows developers to build applications directly on top of Meta’s Llama 3 and Llama 4 models. This move could significantly expand third-party access to Llama models, beyond Meta’s own platforms such as Facebook, Instagram, and WhatsApp. The API supports model fine-tuning, evaluation, and seamless integration through lightweight SDKs.
I felt that the interview with Databricks CEO Ali Ghodsi was more of a PR exercise, mainly intended to showcase how Databricks clients are using Llama. However, it seemed that Zuckerberg is increasingly leaning toward the distillation process. In my view, distillation reduces the risk of Meta’s Llama models underperforming competitors, since superior models—such as DeepSeek V3 or GPT 4o—can be distilled and layered on top of Llama. Ali Ghodsi pointed out that when DeepSeek R1 was released, Databricks customers began using it on top of Llama via the distillation process (minute 1:24:52).
“But I think the reality is-part of the value around open source is that you can mix and and match-so if another model like DeepSeek is better, Queen is better at something, as developers, you have the chance to take the best parts of the intelligence from different the models and produce exactly what you need, which is going to be very powerful," Zuckerberg said (min 1:23:34).
“The distillation thing, I think is going to be a real big deal as we get into the world of different models,” Zuckerberg added (min 1:30:37).
Oh so not insights at all into the release of behemoth, llama 4 reasoning models etc?
Distilling from closed sourced models like gpt 4o should not be legal right?
Maybe you can expand a bit what you mean here (for non expert readers like me)